はじめに
gnuplotで、plotコマンドでグラフを描画した後に、数点のデータをグラフに追加したいことがあると思います。後々にも、その描画を再現する必要があれば、その数点のデータファイルを作成して、プロットのスクリプトを、そのデータも表示するように修正することになりますが、その場限りで、数点だけデータを足して見てみたい場合には、データファイルをわざわざ作るのが億劫になります。
そのようなときにコマンドラインでデータを入力して表示する方法について説明します。
コマンドをスクリプトファイルに記載してload <スクリプトファイル>で実行している場合に、データファイルを作成せずに、スクリプトファイルに含めるようにするときにも使えると思います。
スクリプトファイルにコマンドだけでなく、データも含めて、1つのファイルだけでグラフが表示されるようにしたいという場合にも使えると思いますが、一般的にはデータファイルとスクリプトファイルは分けた方がその後の再利用はしやすいと思います。
で、本題に戻りますと、インラインデータという用語がわかれば、
gnuplot> help inlineで、方法はわかりますが、以下に実際の使用例を示します。
使用例
例えば次のようなグラフをplotしたとします。
この記事はセパレータはcommaだとします。1行目でそのように指定しています。
gnuplot> set datafile separator comma
gnuplot> p 'sample-data.csv' w lp pt 7 ps 0.2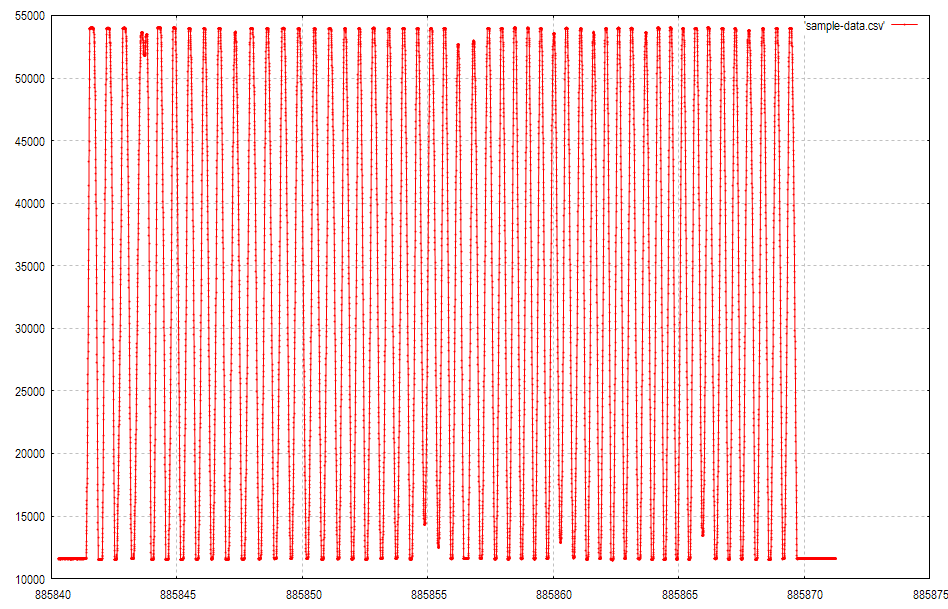
- ちなみに、gnuplotのコマンドはコマンド名が確定できるところまで省略できますが、”p”は特別に1文字だけで”plot”を意味するようです。(pではじまるコマンドは”pause”, “print”, “pwd”などもあり1文字では確定されないので)
- コマンド名が確定できるところまでというルールも有効なので、”plot”コマンドとしては、”pl”, “plo”などでもOKです。
- “w”は”with”の省略形、”lp”は”linespoints”、”pt”は”pointtype”、”ps”は”pointsize”の省略形ですが、”lp”, “pt”,”ps”等は確定するところまでというルール外の省略形です。確定するところまでですと”lines”, “pointt”, “points”までとなります。
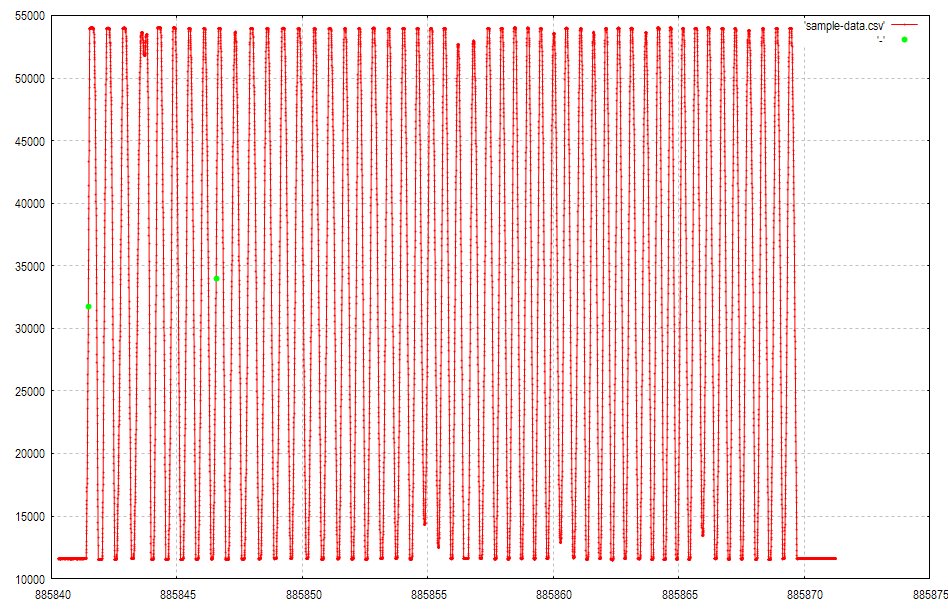
このグラフに(885841.468475, 31711), (885846.563742, 34001)の2点を追加でプロットしたいとします。
方法1: ‘-‘を使う方法
以下のようにコマンド入力します。1行目の “ ,“ 以降が追加データのプロット部分で、ファイル名を ‘-‘ として、描画の修飾要素を記載して改行を打ち込むと、データの入力が求められます。
gnuplot> p 'sample-data.csv' w linesp pt 7 points 0.2, '-' w p pt 7 ps 1
input data ('e' ends) > 885841.468475, 31711
input data ('e' ends) > 885846.563742, 34001
input data ('e' ends) > e“input data (‘e’ ends) > “というプロンプトに続けて必要な行数分のデータを入力し、データ入力終了時は”e“の1文字だけを入力します。
以下のように追加した点が緑の○で2点表示されました。
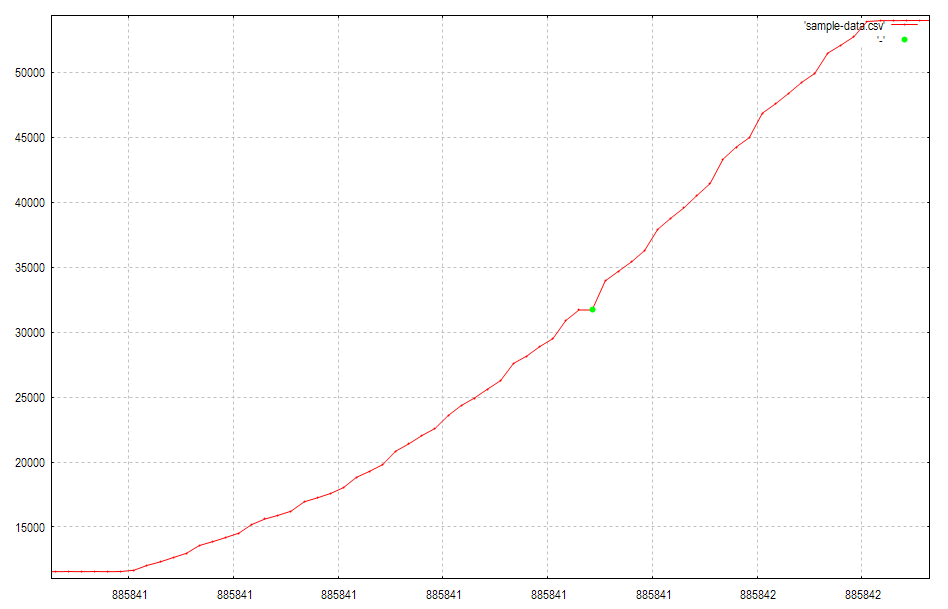
右ドラッグで1点目の部分を拡大すると、以下のようになり、追加した点は、縦軸値が変化していない点でした。右ドラッグで拡大できない場合はキーボードでmを押すとできるようになるかもしれません。
windows版のgnuplot (wgnuplot.exe)での注意点は、データをペーストする場合には、OS標準のCtrl-vではなく、wgnuplotのコマンド画面の地の部分を右クリックして表示される “Shift-Ins” (InsはInsertキー)を使うことです。Ctrl-vを使用すると、データの先頭に何かしら文字化けした文字が入り、うまく描画できませんでした。同様に、wgnuplot.exeでは、Ctrl-cではなく、Ctrl-Insを使わないとうまくコピーできない場合があります。
方法2: 名前付きデータブロックを使う方法
方法2の名前付きデータブロックを使う方法はgnuplot ver 5から使用できます。
まず表示するための「名前付きデータブロック」を作成します。名前は”$”で始まる任意の名前で良いので、ここでは $datとします。またデータ終了のマーカーを決めます。ここでも名前は任意なので”e“とします。このデータ終了のマーカーを “<<“の右に書きます。
help inlineの例ではデータ終了のマーカーは “EOD” となっています。データ終了のマーカーは複数文字でも可ですが、短い方が入力は楽です。
gnuplot> $dat << e
885841.468475, 31711
885846.563742, 34001
e「名前付きデータブロック」は異なる名前にすれば複数個作成できます。
このあとに、このデータブロックをファイル名に指定して、通常の描画を行います。すなわち、方法1の’-‘を$datに置き替えます。
gnuplot> p 'sample-data.csv' w linesp pt 7 points 0.2, $dat w p pt 7 ps 1方法1の注意点と同様に、windows版のgnuplot (wgnuplot.exe)での注意点は、データをペーストする場合には、OS標準のCtrl-vではなく、wgnuplotのコマンド画面の地の部分を右クリックして表示される”Shift-Ins” (InsはInsertキー)を使う必要があります。
どちらの方法が良いか
1回きりの描画で、pointtype, pointsize等の修飾要素を含めて修正がないなら、方法1でも良いですが、大抵は描画した後で、ちょっと変えて表示したいということが多いので、基本は方法2が良いのではないかと思います。方法1ですと、データ入力部分を含めて、再度入力する必要がありますので。
方法1も方法2もヒアドキュメントといわれるものです。
shでは 手動入力データ | 標準入力(stdin)となりますが、方法1はそれと同じ感じです。
(shはUNIXのシェル、”|”は出力を入力につなぐパイプ)
方法2は 手動入力データ | $<datablock>とできるようにしたことで、データブロックを複数個作ることができ、複数データブロックをplotに追加することができて、gnuplot終了まで使えるようになったということかと思います。
おまけ
名前付きデータブロックのデータ表示
help inlineの説明では、作成した名前付きデータブロックは
gnuplot> undefine <名前付きデータブロック名>で削除できると書いてあるだけで、作成した名前付きデータブロックのデータを確認する方法についての説明がありません。
作成した名前付きデータブロック $datのデータの表示は、コマンド一発ではないですが、以下のコマンドでできました。名前付きデータブロックはarrayの一種のようです。コマンド一発で表示できるコマンドをご存じならお知らせいただけるとありがたいです。修正します。
gnuplot> do for [i=1:|$dat|] {pr $dat[i]}ちなみに、|$dat|で名前付きデータブロック$datの行数が表示されるので、上のコマンドは1~最終行まで、1行ずつ表示するということになります。
名前付きデータブロックは何の解釈もされずに、行ごとに格納されます。何の解釈もされずに格納されるので、セパレータで区切られた数値に限らず、英数字の並びを格納可能です。セパレータで区切られた数値でない場合は、plot等をしようとするとエラーになるだけです。
もうちょっと簡単にならないかなぁと思って、ユーザー定義関数にこのdo for文を設定しようとしたら、それはできませんでした。そこで、文字列変数のマクロ置換を使うと以下のコードでできました。
1 gnuplot> nd='$dat'
2 gnuplot> prnd="do for [i=1:|@nd|]{pr @nd[i]}"
3 gnuplot> @prndnd: named datablock名: 名前付きデータブロック名
prnd: print nd: 名前付きデータブロック名をprintする
文字列変数のマクロ置換によって、
3行目の @prnd は
2行目の do for [i=1:|@nd|]{pr @nd[i]} に置換され
1行目の設定により更に do for [i=1:|$dat|]{pr $dat[i]} に置換されます。
上の設定をした状態で、ファイル名$dat2の名前付きデータブロックのデータを表示させる場合は以下のコマンドを入力します。
gnuplot> nd='$dat2'
gnuplot> @prnd起動時に自動実行されるgnuplot.iniに2行目の以下の設定を記載しておけば、
prnd="do for [i=1:|@nd|]{pr @nd[i]}"以下のコマンドで名前付きデータブロック$<datablock_name>のデータの表示ができることになります。
gnuplot> nd='$<datablock_name>'
gnuplot> @prndしかし、それほど文字数が減るわけでもないので、素直に、以下のコマンドを打つ方が楽そうです。
gnuplot> do for [i=1:|$dat|] {pr $dat[i]}設定した文字列変数のマクロ置換の方法を使う場合は、nd, prndの名前を覚えておく必要がありますが、それほど名前付きデータブロックを使う機会はないので、使う頃には忘れていそうです。print 名前付きデータブロックが思い出せれば良いですが。
名前付きデータブロックのデータ保存
コマンドラインで作成した名前付きデータブロックのデータを、ファイルに保存したいこともあるかと思います。ファイルに保存するくらいなら、最初からファイルに保存してplotコマンドで描画すれば良いと思いますが、対話的にコマンドラインで修正していって最終的に保存したくなることもあるかと思います。
上の@prndではコンソール(stderr)に名前付きデータブロックのデータが出力されていましたが、出力先をファイルに変更します。
printの出力先はデフォルトではstderrです。print ‘-‘で出力先はstdoutになり、ファイル名を指定するとそのファイルに出力されます。
以下は出力先を’dat.csv’ファイルにする例です。最後に”set print”することで、出力先はデフォルトのstderrに戻ります。実装方法によりますが、最後に出力先をファイルから変更しないとストリームがフラッシュされずに全てのデータがファイルに記録されないかもしれませんので、このようなときは、処理が終わったら、ファイルの出力先を変更しておくのが無難です。
gnuplot> set print 'dat.csv'
gnuplot> @prnd
gnuplot> set printまた、printは名前付きデータブロックを引数にとることもできます。以下の例ではndに設定した名前付きデータブロックを、名前付きデータブロック$dat2にコピーします。
nd=’$dat’が設定されていれば、$datが$dat2にコピーされます。
gnuplot> set print $dat2
gnuplot> @prnd
gnuplot> set print名前付きデータブロック名の一覧表示
名前付きデータブロック名の一覧は以下のコマンドで出力されます。名前付きデータブロック名と各データブロックの行数が出力されます。
gnuplot> show variables $showの2つ目の引数はこの名前で始まる変数を表示してくださいという意味で、”$“で始まる変数は名前付きデータブロックなので、名前付きデータブロックが表示されます。
(参考) tableを用いた名前付きデータブロックのデータ表示
2列であれば以下の方法もありますが、出力される数値がset formatで変わってくるのでこれもいまひとつです。splotでは3列の出力もできました。
gnuplot> set table
gnuplot> p $dat
# Curve 0 of 1, 2 points
# Curve title: "$dat"
# x y type
885841 31711 i
885847 34001 i
gnuplot> unset table1列目のデータの小数部分が表示されていませんが、これはset formatで指定すれば出てきます。
またtableモードでは最終列にフラグ文字が出力されますが、その意味は以下のとおりです。
| フラグ文字 | 意味 |
|---|---|
| i | その点が有効な範囲内にある場合 |
| o | 範囲外の場合 |
| u | 未定義値 (undefined) の場合 |
たとえば、$datの2点目が範囲外になるように横軸範囲を指定してコマンドを実行すると以下のように範囲外の2列目のフラグ文字が”o“になります。
gnuplot> set table
gnuplot> p [885840:885842] $dat
# Curve 0 of 1, 2 points
# Curve title: "$dat"
# x y type
885841 31711 i
885847 34001 o
gnuplot> unset table以下のコマンドだと、1行2列目の値がNaN (Not a Number, 1/0)なのでフラグ文字が”u“になります。
gnuplot> set table
gnuplot> p $dat u 1:($2>32000 ? $2 : 1/0)
# Curve 0 of 1, 2 points
# Curve title: "$dat u 1:($2>32000 ? $2 : 1/0)"
# x y type
885841 NaN u
885847 34001 i
gnuplot> unset table三項演算子で1/0を使ってある条件のときだけ線を出さないというのはgnuplotの定石のひとつです。
set tableは、グラフ表示をしたときに、グラフが何かおかしく、グラフの表示元の数値を表示させてデバッグするときに使う機能と考えるのが良いと思います。
set tableはファイル名を引数に指定すると、ファイルに出力することもできるので、データの量が多い場合は、ファイルに出力して確認するのが良いです。
コメント